
Large Language Models vs Small Language Models: An Engineering Perspective

Overview
Imagine a leaf cutter ant colony building an underground city. Thousands of tiny ants, each no bigger than a grain of rice, working together to accomplish what seems impossible. They cut leaves from trees miles away, transport them underground, cultivate fungus gardens for food, defend against threats, and maintain elaborate tunnel networks.
Now imagine trying to accomplish the same with a single giant creature. It is powerful and intelligent, but it is slow, requires massive resources, and struggles to navigate tight spaces.
This is the choice engineering teams face with AI today: Large Language Models versus Small Language Models.
Large Language Models are like that giant intelligent creature. They can handle almost any task, reason through complex problems, and generate impressive outputs. However, they are expensive, slow, and difficult to deploy in resource constrained environments.
Small Language Models are like specialized ant workers. Each one handles a focused task exceptionally well. When orchestrated together in an agentic colony, they accomplish complex workflows faster, cheaper, and more reliably than a single large model.
This article explores how modern AI systems are shifting from monolithic Large Language Models to coordinated Small Language Model colonies and why this matters for practical deployment.

Understanding the Difference
What Are Large Language Models?
The Basics
Large Language Models are AI systems trained to understand and generate human language by learning patterns from massive text datasets.
The name explained:
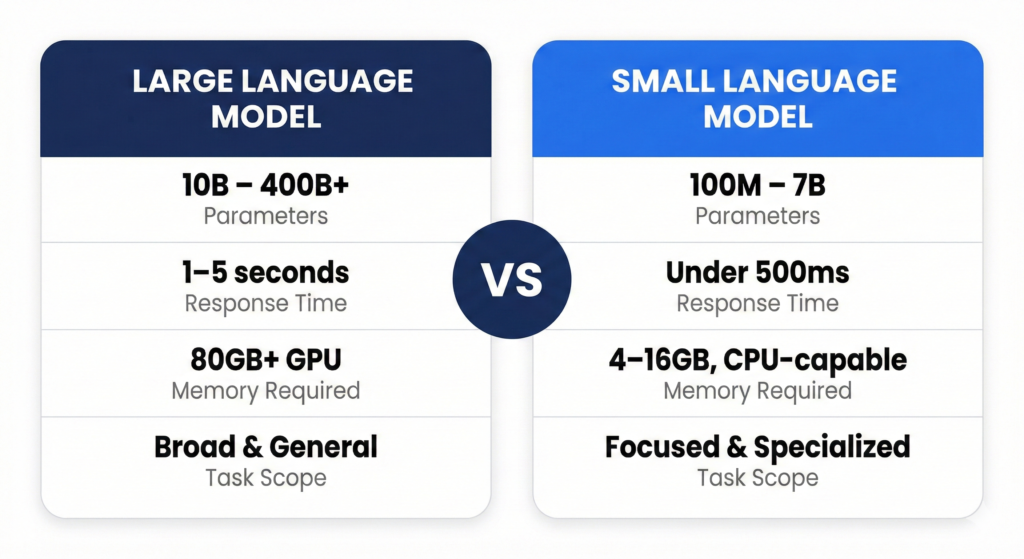
Large refers to 10 billion to more than 175 billion parameters. Parameters are adjustable numerical values that help the model make decisions. Language refers to specialization in processing and generating text. Model refers to a mathematical system that learns patterns from data.
How Large Language Models Are Made
- Data collection involves gathering hundreds of terabytes of text from books, websites, code repositories, and conversations.
- Pre training involves exposing the model to this data billions of times over weeks or months using thousands of GPUs so it learns grammar, facts, and reasoning patterns.
- Fine tuning refines the model for specific tasks using human feedback so it follows instructions accurately.
- Alignment ensures the model behaves in a helpful, honest, and safe way.
How They Work
When you ask a question, your text is converted into tokens, which are numerical representations. These tokens pass through billions of mathematical operations. Each layer detects increasingly complex patterns, from words to sentences to concepts. The model predicts the most likely next token repeatedly until a full response is generated.
An analogy is a massive elephant that has read every library book in the world and can recall patterns to answer your questions.
Popular Examples
- GPT 4 by OpenAI known for reasoning and multimodal capabilities.
- Claude 3 by Anthropic known for long context and nuanced conversation.
- Gemini Ultra by Google known for multimodal understanding and code generation.
- Llama 3.1 405B by Meta known for open source availability and multilingual capability.
Strengths of Large Language Models
- They have broad knowledge and can discuss almost any topic.
- They can perform complex reasoning and handle multi step problems.
- They adapt well to unfamiliar tasks.
- They understand context, tone, and nuance.
- Limitations of Large Language Models
- They are expensive, often costing dollars per million tokens.
- They are slower, often taking seconds to respond.
- They require large memory, often needing high end GPUs.
- They are difficult to deploy on standard hardware.
- They consume significant energy during training and inference.
What Are Small Language Models?
The Basics
Small Language Models are compact AI systems typically ranging from 100 million to 13 billion parameters. They are optimized for efficiency and specific tasks.
The key difference is that Small Language Models are specialists rather than generalists.
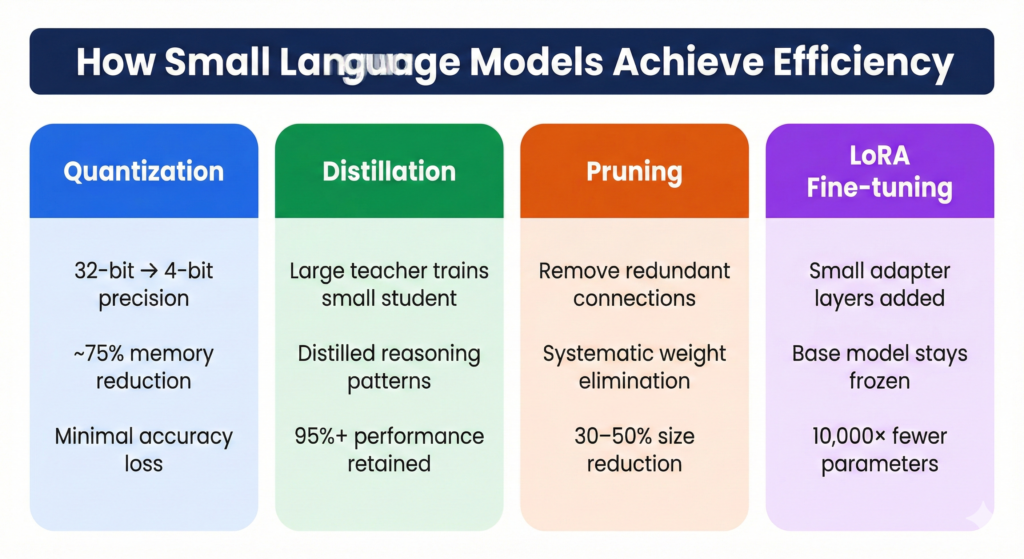
How Small Language Models Achieve Efficiency
- Quantization reduces numerical precision from high precision formats to lower precision formats, reducing memory usage significantly while maintaining performance.
- Knowledge distillation trains a smaller model to mimic a larger model so it achieves similar performance with fewer parameters.
- Pruning removes unnecessary neural connections, making the model smaller and faster.
- Low Rank Adaptation adds small adapter layers for task specific tuning instead of retraining the entire model.
- Architectural improvements such as grouped query attention reduce computation requirements.
Examples of Small Language Models
- Phi 3 mini by Microsoft designed for mobile deployment.
- Mistral 7B by Mistral AI known for strong performance despite smaller size.
- Gemma 2B and 7B by Google designed for efficient multilingual tasks.
- Llama 3.2 1B and 3B by Meta optimized for edge deployment.
- Qwen 3 4B by Alibaba optimized to run efficiently on CPUs.
Strengths of Small Language Models
- They are fast and often respond within milliseconds.
- They require fewer resources and can run on CPUs or consumer GPUs.
- They are much cheaper per query.
- They can be deployed on edge devices such as phones and embedded systems.
- They can run offline, improving privacy and security.
Where Small Language Models Excel
- They perform well in structured tasks such as classification, summarization, and extraction.
- They are effective in repetitive workflows such as tagging and routing.
- They are useful in domain specific applications such as medical or legal processing.
- They are ideal for resource constrained environments.
- They are suitable for high volume workloads
Why SLMs Are Becoming More Relevant
Several industry trends explain the growing interest in smaller models:
Operational Constraints
Not every organization can support large-scale GPU infrastructure. Many enterprises operate in restricted compute environments where smaller models are easier to deploy, maintain, and scale horizontally.
Cost Awareness
Running large models continuously is expensive. Processing 10 billion tokens monthly with GPT-4 costs roughly $300,000. The same workload handled by a self-hosted 3B model costs around $5,000. For applications where the majority of queries are routine and structured, LLM-level capability simply isn’t required.
Explainability and Regulatory Fit
LLMs with hundreds of billions of opaque parameters are difficult to audit. SLMs offer simpler, more interpretable architectures — a meaningful advantage in regulated industries like healthcare, finance, and legal where explainability is not optional. The EU AI Act and similar frameworks increasingly require organizations to justify model behavior, and smaller models are naturally better positioned for this.
Privacy and Data Sovereignty
Most organizations cannot justify the cost of hosting LLMs, and many cannot afford to share sensitive data with external LLM providers. GDPR, HIPAA, and SOC2 compliance often mandates on-premises processing. SLMs running locally address both constraints simultaneously — keeping proprietary code, patient records, and customer data inside organizational boundaries.
From Monolithic Models to Agentic Systems
Early AI applications relied on single large models to handle everything: understanding inputs, reasoning, retrieving information, and generating output.
This approach works but does not scale efficiently.
A better pattern is emerging: agentic architecture. In this approach:
- Different agents handle distinct responsibilities
- Each agent uses only the context it needs
- Outputs are validated against structured evidence
- Tasks are executed sequentially or in parallel
In such systems:
- Smaller models can power individual agents
- Larger models can be reserved for genuinely complex steps
- Rule-based components handle deterministic validation
This architecture improves reliability, reduces hallucination, and lowers resource consumption.
Instead of asking one large model to “do everything,” engineers design pipelines where:
- One agent analyzes structure
- Another extracts APIs
- Another generates documentation
- Another validates results
This modular approach significantly improves control and observability.
Practical Engineering Lessons
From building agentic AI systems using both large and small models, several lessons emerge:
SLMs Require Tighter Guardrails
Smaller models degrade faster without explicit constraints. Effective SLM deployments use explicit, narrow prompts, limited tool calls, structured intermediate representations, and evidence-based validation rather than open-ended generation.
The Evidence Layer Matters
One of the most effective techniques when working with SLMs is maintaining a structured evidence layer derived directly from source artifacts — files, dependencies, configurations. Generated content is then validated against this evidence rather than trusting the model’s output blindly. This dramatically reduces hallucinations and improves consistency.
Importantly, this is not self-validation — asking the same model to check itself. It is external validation against independently verified ground truth. The same technique applies to LLMs, but it becomes critical with SLMs where smaller context windows and reduced reasoning capacity make external grounding more essential.
Specialized Agents Outperform Generalized Prompts
Splitting responsibilities across multiple focused agents produces better results than using a single general-purpose prompt, even with a powerful LLM. Each agent operates within a narrow scope with specialized prompts and validation rules, making SLMs viable even in workflows that appear complex at the system level.
Hybrid Strategies: The Practical Path Forward
Rather than choosing between LLMs and SLMs, leading engineering teams are adopting hybrid approaches where routing logic determines which model handles which task:
- SLMs handle routine, structured, high-volume processing
- LLMs handle advanced reasoning, ambiguous inputs, and quality-critical outputs
- Rule-based validation ensures correctness at every step
A well-designed routing layer can direct 80% of tasks to SLMs and escalate only the remaining 20% to LLMs. Teams that have implemented this pattern report 60–70% cost reduction while maintaining output quality comparable to pure LLM approaches.

Looking Ahead
As model ecosystems mature, organizations will increasingly manage fleets of specialized models rather than relying on a single best model. Key developments to watch:
- Intelligent routing AI systems that automatically select models based on task complexity and cost thresholds
- Multi-agent pipelines frameworks like LangGraph making agentic architectures more accessible
- Domain-specialized SLMs models trained exclusively on medical, legal, or financial corpora
- Evidence-grounded generation broader industry adoption of retrieval-augmented generation and validation layers
- On-device AI SLMs running entirely on smartphones and edge hardware
The future of AI deployment is not about the biggest model winning. It is about smarter system design, knowing when to use raw capability and when to use efficiency, and building the orchestration layer that routes intelligently between the two.
Conclusion
LLMs unlocked powerful capabilities that seemed out of reach just a few years ago. SLMs are enabling something equally important: practical, scalable, responsible AI deployment where cost, privacy, speed, and explainability are non-negotiable.
The question is no longer “LLM or SLM?” It is how to orchestrate both effectively using agentic architectures to decompose problems, evidence driven workflows to validate outputs, and hybrid routing to match the right model to each task.
Success in AI engineering increasingly comes from system design, not just model selection.
References
- Yao et al., 2022 – ReAct: Synergizing Reasoning and Acting in Language Models
https://arxiv.org/abs/2210.03629 - Shazeer et al., 2017 – Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
https://arxiv.org/abs/1701.06538 - Chen et al., 2023 – FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
https://arxiv.org/abs/2305.05176