
AI at the Edge: Deploying Secure LLMs in Fully Isolated

AI at the Edge: Deploying Secure LLMs in Fully Isolated Environments
The Offline Deployment Challenge: When AI Needs the Internet, but Your Data Can't Leave
A hospital licensed an LLM for rapid report drafting, but deployment stalled when legal and compliance
intervened. Patient data protection such as HIPAA and strict network policy blocked all outbound internet
traffic, making the vendor’s cloud-based SaaS endpoint unreachable. More importantly, sending sensitive
patient records to an external AI service introduces risks that many healthcare organizations simply cannot
accept. This critical challenge demonstrates the growing need for secure offline AI deployment and
on-premises AI inference in highly regulated environments.
This isn’t a healthcare-only problem. The same wall shows up across many regulated industries:
● Financial institutions operating trading and risk systems on isolated market-data networks.
● Energy utilities managing SCADA and industrial control systems physically separated from corporate IT.
● Manufacturing plants running quality-inspection AI on factory-floor networks that never touch the internet.
● Government agencies operating within highly restricted environments with strict data residency requirements.
For these organizations, cloud-based AI services are often not an option. They require private AI
infrastructure capable of running entirely within their own environment, with no dependency on external networks, public model repositories, or third-party APIs.
Modern AI stacks are notoriously complex and internet-dependent, making disconnected on-premises
deployment a significant challenge for regulated organizations. The challenge isn’t simply deploying a
model. It’s deploying an entire enterprise AI platform in a disconnected environment.The Enterprise AI
Inference Platform solves this by managing every layer of the dependency chain, enabling a fully isolated
LLM inference stack with zero external dependencies.
How Cloud2Labs’ Offline Deployment Solution Closes the Gap
The Enterprise AI Inference Platform (EI) automates secure LLM deployment via a two-stage architecture.
The core stack including Kubernetes components, AI Inference Engine, Identity providers(IdP), API
gateways, packages and model artifacts is pre-staged to an Internal Artifact Repository, from which the
isolated inference machine pulls artifacts over the local network.
This approach delivers offline AI deployment, zero runtime internet access,
hardened security isolation, and deterministic reproducibility through a single configuration toggle. EI also
automatically resolves non-obvious pitfalls, such as blocking silent internet fallbacks, automating tooling workarounds
(OCI chart rewrites, environment bootstrapping), and packaging all necessary binaries
internally to eliminate external source dependencies.
Once staging is complete, the target inference environment can be completely isolated from the internet while continuing to operate normally.
Solving the Hidden Complexities of Offline AI Deployments
One of the biggest surprises was discovering how many components silently assume internet access.
Even after mirroring container images and model weights locally, deployment failures continued to appear.
Some components attempted fallback pulls from public registries when artifacts were unavailable. Package
managers tried reaching external repositories for updates. Model-serving frameworks attempted metadata
validation against public model hubs. Certain deployment tools bypassed configured mirrors entirely. In
some cases, services appeared healthy but were silently waiting for responses from unreachable external
endpoints.
One particularly challenging issue involved a model runtime that appeared to start successfully but
remained unresponsive for nearly thirty minutes. There were no visible errors. The service was waiting for
an external validation request that could never complete because internet access had been removed.
These hidden dependencies are rarely visible in development environments because connectivity masks
them. They only surface when organizations attempt to deploy AI in truly isolated networks.
Successfully operating AI in disconnected environments requires identifying and eliminating every hidden
dependency across the software supply chain.
Offline Deployment in the Enterprise AI Inference Platform: How It Works
When offline deployment is enabled, every component of the EI deployment pipeline pulls from the
Internal Artifact Repository instead of the internet. The process involves two key stages, typically on
separate machines:
Stage 1. Asset Preparation: The staging environment populates the Internal Artifact Repository with:
● Container images
● Kubernetes dependencies
● Helm charts
● Python packages
● Operating system packages
● Infrastructure automation assets
● AI model weights
Once staging is complete, repository synchronization is disabled to ensure only approved artifacts are
available to production environments.
Typical staging requirements:
● 80 GB minimum free storage
● Internet connectivity during artifact collection
● Administrative access
Stage 2. Isolated Deployment: The deployment package is transferred to the target environment through
approved methods such as secure copy, removable media, or internal distribution systems.
Internet access is then blocked, and deployment proceeds using only internally hosted artifacts.
Everything required for deployment, including infrastructure binaries, packages, images, and models, is
sourced locally.
Typical deployment requirements:
● 64 GB RAM minimum for CPU-based model serving
● 80 GB free storage
● Administrative access
● Local network connectivity to the artifact repository
Offline AI Deployment Architecture:
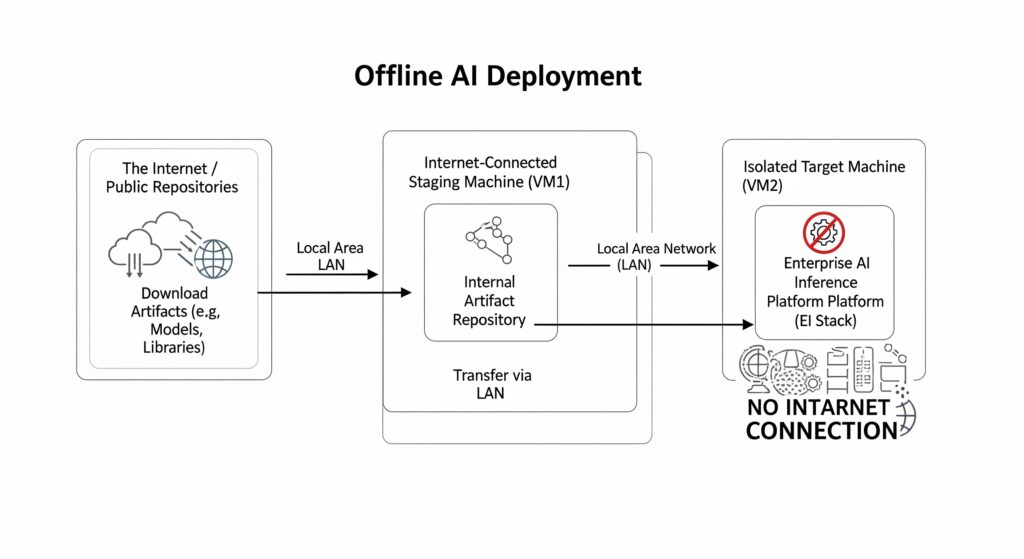
The low-level steps below detail the automatic process of bringing the AI inference stack online:
● Network isolation via iptables to permit only LAN-based traffic.
● Bootstrapping apt, pip, and cluster tools from the Internal Artifact Repository.
● Kubernetes provisioning using binaries served from internal storage.
● Redirection of containerd image pulls and Helm OCI charts to the internal repository.
● LLM engine initialization with offline flags and model weights loaded from local storage.
Hardware Requirements for Secure Offline LLM Deployment
Both environments must be connected through the same internal network, with the staging environment
remaining accessible throughout deployment.
|
Requirement |
(VM1) Staging Environment |
(VM2)Inference Environment |
|---|---|---|
|
Internet |
Required during staging |
Fully blocked before deployment |
|
Disk |
80 GB free minimum |
80 GB free minimum |
|
RAM |
8 GB minimum |
64 GB minimum (LLM inference engine loads weights into memory) |
|
CPU |
No special requirement |
16 cores recommended |
|
OS |
Ubuntu 22.04 LTS |
Ubuntu 22.04 LTS |
|
Network |
Reachable from VM2 on port 8082 |
LAN access to VM1 only; no public internet |
|
Access |
Root or sudo privileges |
Root or sudo privileges |
Internal Artifact Repository Structure
The Internal Artifact Repository functions as the essential architectural backbone for offline AI deployment, centralizing all necessary components to ensure a seamless, internet-independent deployment experience. The setup script creates six types of repositories in the Internal Artifact Repository. Each one maps to a specific layer of the enterprise AI deployment stack.
Repository | Type | What it holds |
virtual / local / remote Docker repository | Docker | ~40 container images (aggregated for containerd). |
local / virtual Helm repository | Helm | 10 core service charts. |
local / virtual PyPI repository | PyPI | ~30 Python packages for automation. |
virtual Debian repository | Debian | Pre-cached Ubuntu APT packages. |
generic binaries storage | Generic | K8s binaries, cluster tools, pip wheels, and collections. |
generic model storage | Generic | Full HuggingFace snapshots of LLMs. |
Validated Models for Offline LLM Deployment
The following models are validated for end-to-end offline deployment. While others can be added manually by uploading weights to the Internal Artifact Repository, they are not pre-tested in this configuration.
|
Model |
HuggingFace ID |
Size |
Access |
Recommended for |
|
Llama 3.2 3B Instruct |
meta-llama/Llama-3.2-3B-Instruct |
~6.5 GB |
Gated |
Smallest model; fastest stack verification. |
|
Qwen3 0.6B |
Qwen/Qwen3-0.6B |
~1.2 GB |
Open |
Lightweight testing. |
|
Qwen3 1.7B |
Qwen/Qwen3-1.7B |
~3.4 GB |
Open |
Balanced CPU performance. |
|
Qwen3 4B |
Qwen/Qwen3-4B |
~7.6 GB |
Open |
Higher quality responses. |
The Llama 3.2 3B Instruct model remains our primary recommendation for initial deployment due to its compact hardware footprint and rapid initialization, facilitating the fastest end-to-end stack verification.
Organizations can onboard additional LLMs by importing approved model artifacts into the Internal Artifact Repository and performing validation through the standardized staging process to ensure consistent offline performance.
Maintaining Artifact Security and Consistency
Disconnected deployment shifts continuous upkeep to the organization. Managing this artifact lifecycle for security and reproducibility requires:
- a periodic refresh cycle for all cached artifacts.
- enforcing version pinning to immutable versions, and
- validating new versions on the staging machine before promotion.
The Real Challenge Isn't the Model
Many organizations spend months evaluating which LLM to deploy.
In practice, model selection is rarely the primary obstacle.
The bigger challenge is building a reproducible AI platform capable of operating across cloud, on-premises, edge, and disconnected environments while maintaining security, governance, and operational consistency.
At Cloud2Labs, we’ve found that successful enterprise AI deployments depend less on the model itself and more on the infrastructure, automation, and operational discipline surrounding it.
Organizations that solve these challenges today will be best positioned to deploy AI wherever their data resides, whether that’s a hospital, manufacturing facility, financial institution, government agency, or edge location.
As enterprise adoption accelerates, private AI infrastructure, sovereign AI architectures, and self-hosted LLM deployments will become increasingly important for organizations that require complete control over their data, models, and operational environments.