
Building Vaani Sahayak: A Sovereign AI Voice Assistant for India’s Government Schemes

India has over 2,000 government welfare schemes. Most citizens don’t know what they’re eligible for. What if they could just ask — in Hindi or Telugu — and hear the answer spoken back?
That’s Vaani Sahayak (वाणी सहायक) — a voice assistant for Indian government schemes built entirely on Indian AI models. No OpenAI, no Google, no API keys leaving the country. A fully sovereign AI stack that can run air-gapped inside a government network.
Here’s the story of how we built it.
Why Sovereign AI Matters for Government Applications?
The Indian AI ecosystem has matured rapidly. Models like Param-1 from BharatGen (the IIT consortium) and Indic Parler-TTS from AI4Bharat are production-capable for Indian language AI applications. They’re open-source, Apache 2.0 licensed, and can run entirely on your own infrastructure.
For a government-facing AI application handling citizen data, that matters. No data leaves the network. No vendor lock-in. No per-query API costs. We wanted to prove this sovereign AI architecture could work end-to-end.
Our model choices:
- Param-1 (BharatGen / IIT Madras) — a 2.9B parameter Hindi/Telugu instruction-following LLM
- Indic Parler-TTS (AI4Bharat) — the first open-source text-to-speech model for Indian languages
- MiniLM embeddings — for fast retrieval across 2,086 government schemes
The Architecture of the Vaani Sahayak AI System
The pipeline is straightforward: a citizen asks a question in Hindi, we find the most relevant schemes using embedding similarity search over 2,086 records scraped from MyScheme.gov.in, inject the top matches into Param-1’s context for a grounded AI responses, and synthesize the response as streaming audio through Indic Parler-TTS.
The system runs on a FastAPI backend, React frontend, and uses Server-Sent Events (SSE) streaming, so users see text and hear audio progressively — not staring at a loading spinner for 10 seconds.
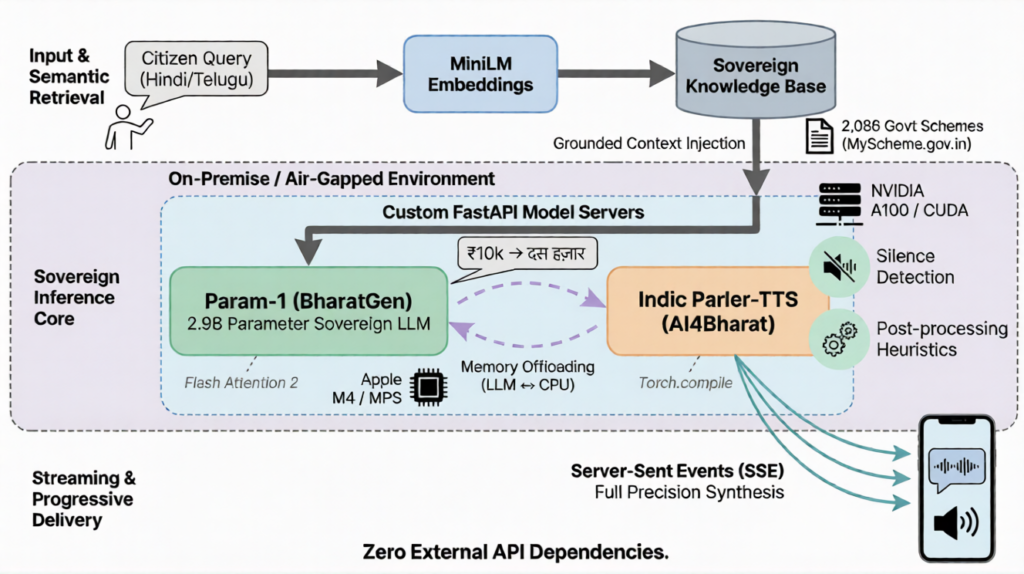
The AI Model Serving Challenge
Our first instinct was to use off-the-shelf LLM serving frameworks like vLLM or MLX. Neither supported Param-1’s custom transformer architecture out of the box. Rather than fighting the tooling, we wrote lightweight FastAPI model servers that wrap HuggingFace Transformers directly and expose OpenAI-compatible APIs. Same interface the backend expected, full control over inference.
This turned out to be a blessing. Custom servers let us implement features the frameworks wouldn’t have given us — memory management between models on constrained hardware, streaming token generation with fine-grained stop conditions, and the ability to tune generation parameters exactly to what Param-1’s model card recommends.
Getting Text-to-Speech (TTS) Right on Apple Silicon
Development happened on a MacBook Pro M4. Getting the LLM inference running locally was one thing — getting high-quality Hindi text-to-speech synthesis on Apple’s MPS GPU acceleration was another challenge entirely.
Several optimizations that are standard on NVIDIA GPUs — half-precision inference, scaled dot-product attention, torch.compile, either degraded audio quality or didn’t work on MPS. We had to find the right configuration through trial and error: full precision inference, careful memory management, and explicit cleanup after every synthesis pass.
The TTS model also had a tendency to generate gibberish audio past the actual speech — a known issue when autoregressive speech models hit their token limit without a clean stop signal. We built audio post-processing heuristics to detect silence boundaries and trim cleanly.
With both models needing several gigabytes of GPU memory on a 16 GB machine, we also had to get creative with memory, offloading the LLM to CPU during speech synthesis and bringing it back after.
Streaming Changes Everything
Raw end-to-end latency on a laptop is 8-15 seconds. That’s too slow for a voice assistant AI system. But real-time streaming responses transform streaming transforms the experience, first text tokens appear in under a second, first audio plays within a few seconds. The user is reading and listening long before the full response is ready.
Making this work required solving a few interesting problems:
- Chunking Hindi text at natural linguistic boundaries for TTS
- Normalizing currency and numbers for speech synthesis (₹10,000 becomes दस हज़ार रुपये)
- Coordinating frontend audio playback when streaming chunks arrive at unpredictable intervals
Moving AI Inference to NVIDIA GPUs
The laptop was a development environment. For production-grade AI inference latency, we deployed the TTS model to NVIDIA GPUs via Kubernetes, a separate CUDA-optimized inference server with automatic attention backend detection (Flash Attention 2 on newer GPUs, SDPA on V100s).
The backend has a smart routing layer: try the GPU inference server first, fall back to local if unavailable. On an NVIDIA A100 GPU, per-sentence speech synthesis latency dropped from tens of seconds to sub-second response time.
The full deployment package includes:
- Docker container builds
- Kubernetes manifests
- API gateway configuration
- Support for token-based authentication and OAuth2 security
What We Shipped
A working Hindi/Telugu AI voice assistant that answers questions about 2,000+ government welfare schemes. Every model is open-source AI . Every inference runs on our infrastructure. No data leaves the network.
- 2,086 government schemes indexed from MyScheme.gov.in
- 3 models — all open-source, all Apache 2.0
- 2 languages — Hindi and Telugu, with more planned
- Zero external API dependencies — fully sovereign, fully offline-capable
- Built with Claude Code as a pair programmer across the entire journey
Reflections on Building Sovereign AI
Sovereign AI for India is production-ready for domain-specific work. Indian LLMs aren’t trying to be GPT-4 alternatives. For structured retrieval over government datasets in Indian languages, they deliver.
The hard problems aren’t where you expect them. We anticipated model quality challenges. Most of our time went into serving AI infrastructure engineering, memory orchestration, audio post-processing, and the dozen small things between “model works in a notebook” and “user hears a clean answer.”
Streaming AI responses is not optional for voice systems. Progressive delivery — text appearing as it’s generated, audio playing sentence by sentence — is what makes a multi-second AI pipeline feel responsive.
What's Next for Vaani Sahayak
The roadmap for Vaani Sahayak AI voice assistant includes:
- Speech-to-text input for voice queries
- Support for more Indian languages
- Running the LLM on GPUs
- Fine-tuning models on scheme-specific datasets
- Pilots at Common Service Centers (CSCs)
The code is open-source at github.com/cld2labs/VaaniSahayak .
Built at Cloud2 Labs Innovation Hub. Vaani Sahayak is a demo project — not an official government service. Always verify scheme information at myscheme.gov.in.