
OrchestROUTER: How Intelligent Query Routing Reduces AI Cost Without Sacrificing Quality

OrchestROUTER: How Intelligent Query Routing Reduces AI Cost Without Sacrificing Quality
Routing across enterprise Qwen models with the RouteLLM framework
Not every query needs your most powerful Large Language Model (LLM).
A customer support assistant fielding a million questions a month sends “What are your hours?” to the same premium model it would use to “Analyze three quarters of financial performance and identify anomalies.” One of those questions needs a 32-billion-parameter reasoning engine. The other does not. Yet most enterprise AI deployments send both to the same model, because the system has no idea which is which.
The mismatch is the problem. Reach for the largest model on every greeting, every “thanks,” every one-line lookup, and you spend heavy capability on queries that never asked for it. Reach for the smallest model on everything and the genuinely hard queries get answers that don’t hold up.
What if the system could tell the difference before it answered, sending the simple requests to a small, fast model and reserving the premium reasoning models for the queries that genuinely need it?
That’s OrchestROUTER, an intelligent query router that decides, in under a tenth of a second, whether an incoming query needs a premium reasoning model or a lightweight one. It’s built on RouteLLM, the open-source routing framework from UC Berkeley and Anyscale, and it routes between two enterprise Qwen models, matching each query to the right one without giving up quality on the queries that matter.
Our goal wasn’t to build another chatbot. It was to answer a simple question: can intelligent routing reduce AI inference cost without sacrificing quality?
In our experiments, a threshold of 0.2 routed roughly 78% of requests to the smaller Qwen3-4B model while preserving intuitive complexity-based escalation for technical and reasoning-heavy queries.
Here’s the story of how we built it.
Why Intelligent Routing Matters for Enterprise AI
The trap is a real dilemma. Pick one model for everything and you lose either way.
Commit to the largest model and every trivial query runs on far more capability than it needs. Commit to the smallest model and you do fine right up until a genuinely hard query lands on a model that can’t handle it, and the answer quietly falls short.
Intelligent routing refuses the choice. Send the simple requests to the efficient small model and the complex ones to the premium reasoning model, and you get top-tier quality where it counts without leaning on it everywhere. At scale, intelligent query routing becomes more than a model-selection problem. It becomes a cost-management problem.
Every query routed to a premium reasoning model consumes valuable GPU resources. Those resources could instead be reserved for complex reasoning tasks, agentic workflows, retrieval pipelines, and business-critical interactions.
The goal is not simply model selection. It is allocating the right amount of AI capability to each request.
The research behind RouteLLM’s intelligent LLM routing framework suggests that, depending on the query mix, somewhere between half and two-thirds of typical traffic can go to the smaller model with no meaningful quality loss. That’s a compelling proposition for any enterprise AI stack.
Technology Stack Behind OrchestROUTER
Four open pieces do the work:
- RouteLLM (UC Berkeley + Anyscale): an open-source framework that trains routers on human preference data to predict which queries actually benefit from a more capable model.
- Qwen3-4B-Instruct (small model): a 4-billion-parameter workhorse for factual questions, short explanations, summarization, and everyday conversation.
- Qwen2.5-32B-Instruct (premium reasoning model): a 32-billion-parameter model for multi-step reasoning, ambiguous prompts, technical depth, long-context comprehension, and native-quality multilingual generation.
text-embedding-3-small: the encoder that turns each query into a 1,536-dimension vector the router can reason over, the same encoder used to train the router.
Why Intelligent LLM Routing Is Harder Than It Looks
Our first instinct, everyone’s first instinct, was rules. Long query? Route to the premium model. Contains code? Route to the premium model. Otherwise, the small model. It falls apart immediately. “What is 2+2?” is short and trivial. “Summarize this article in three sentences” can carry 200 words of input yet is simple pattern-matching. Surface features like length and keywords just don’t capture what makes a query hard.
RouteLLM’s insight is to stop guessing and learn from people. Its routers are trained on roughly 100,000 real comparisons from the LMSYS Chatbot Arena, where users pitted two models’ responses against each other and picked a winner. From those preferences the router learns which query characteristics predict that the premium reasoning model produces a meaningfully better answer, and which don’t. No hand-crafted features, no brittle rules. Just preference data doing the work.
OrchestROUTER Architecture for Enterprise AI Routing
The system follows a clean three-tier design.
A React frontend handles query input, response display, and a live dashboard of routing metrics: which model each query went to, and how confident the router was.
A FastAPI backend is where routing happens. It embeds the incoming query, runs the RouteLLM controller to get a decision, dispatches to the chosen model, and logs the query, routing decision, confidence, and latency for later analysis.
An enterprise inference tier serves both Qwen models behind OpenAI-compatible endpoints, secured with bearer-token auth and HTTPS. The backend doesn’t care which model it’s calling, the same interface works either way, which keeps the routing logic clean and the model pair swappable.
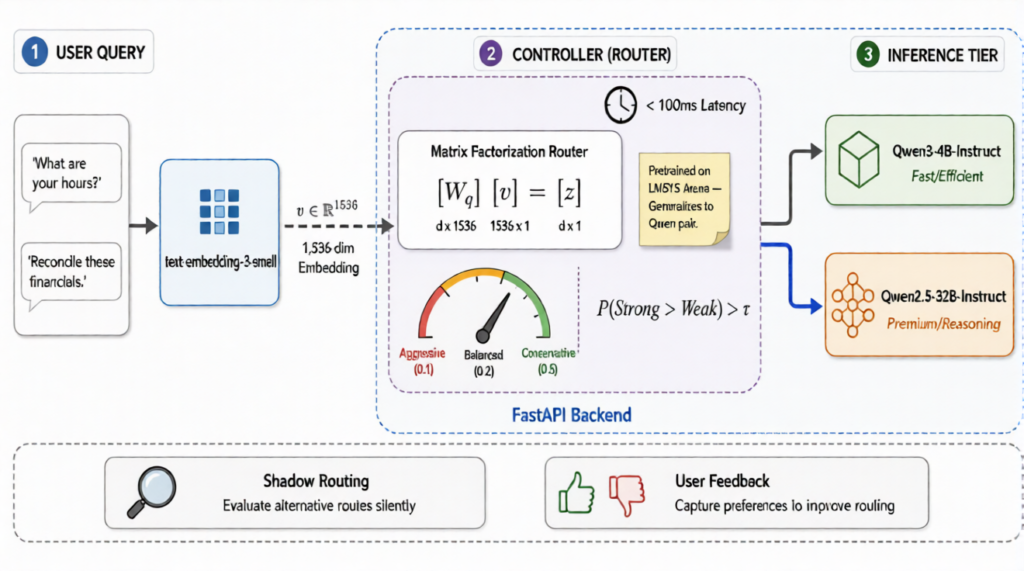
Choosing the Right AI Router: Matrix Factorization
RouteLLM ships four routing methods: Similarity-Weighted Ranking, Matrix Factorization, a BERT classifier, and a Causal LLM classifier. We chose Matrix Factorization because the research showed it matching premium-model quality across benchmarks while sending the fewest queries to the large model, with fast inference (around 50ms) and modest training cost.
The mechanism borrows from how Netflix recommends films. Netflix embeds users and movies into the same vector space and predicts a rating from how well they align. Matrix Factorization embeds queries and models into a shared space and predicts a quality score from their compatibility: roughly the element-wise product of the query and model vectors, summed, plus a learned bias. Train it on preference pairs with a margin loss that pushes the winner’s score at least a full point above the loser’s, and it learns the same kind of pattern a recommender does. Queries that demand deep reasoning pair well with premium reasoning models, while factual lookups score about the same on either.
One subtlety makes it work: the query vectors come from a frozen pretrained encoder, but the model vectors are learned from scratch during training, so they capture routing-relevant behavior rather than anything read off the models’ weights.
The Surprising Part: How RouteLLM Routers Generalize Across Different LLM Models
Here’s the result we didn’t expect. RouteLLM’s pretrained Matrix Factorization router was trained on GPT-4 versus Mixtral comparisons, a completely different model pair from a different era and different families than ours. We mapped our models to the closest arena equivalents (Qwen2.5-32B into the premium gpt-4 slot, Qwen3-4B into a small llama-3-8b-instruct slot) and it simply worked. The router sent our Qwen queries exactly where intuition said they should go.
The takeaway is bigger than our project. The router didn’t memorize GPT-4-versus-Mixtral preferences. It learned general query complexity: reasoning depth, ambiguity, domain difficulty, the things that transfer to any model pair with a real capability gap. In practice, that means a team can apply RouteLLM to its own model pair without retraining, provided the two models differ meaningfully in capability.
Tuning the Dial: Threshold Experiments
The router outputs a win probability, its estimate that the premium reasoning model would beat the small one on a given query. A single threshold turns that probability into a decision: above it, route to the premium model; below it, route to the small model. Lower the threshold and more traffic flows to the smaller model. We tried three.
Threshold | % to Premium | % to Small | Avg. Routing | Routing Behavior |
0.1 | 71% | 29% | 0.40 | Very conservative: most traffic escalates to the premium model; only the clearest easy queries stay small |
0.2 | 22% | 78% | 0.75 | Balanced (sweet spot): clear complexity-based routing emerges; technical/math queries escalate, everything else goes small |
0.3 | 6% | 94% | 0.83 | Aggressive cost savings: only the hardest code & math queries reach the premium model |
> 0.4 | 0% | 100% | 0.85 | Too aggressive: every query routes to the small model , Saturated |
Table 1. Threshold behavior chart: how the win-probability dial shifts traffic between the two models (100-query test set).
Query Category (20 queries each) | Win-Prob. | % to Premium | % to Premium | % to Premium |
Simple factual | 0.06 – 0.27 | 80% | 20% | 0% |
Complex reasoning | 0.05 – 0.18 | 60% | 0% | 0% |
Code generation | 0.11 – 0.37 | 100% | 35% | 10% |
Math & logic | 0.11 – 0.37 | 100% | 55% | 20% |
Creative & open-ended | 0.03 – 0.17 | 15% | 0% | 0% |
Table 2. Per-category routing: share of each query type sent to the premium model across the useful threshold range. At 0.4 and above, every category routes entirely to the small model.
0.2 landed as our sweet spot for general traffic. Greetings, simple facts, and basic explanations went to Qwen3-4B, while technical questions, multi-step reasoning, and complex instructions escalated to Qwen2.5-32B. The win probabilities tracked human intuition closely: “Explain quantum entanglement” scored high, “What is 2+2?” scored low. And the whole control surface is one number a stakeholder can turn without any ML expertise: route more aggressively or more cautiously, your call.
Key Learnings from Building an Intelligent Query Routing System
One thing we learned quickly: the thorniest issue isn’t routing, it’s knowing whether you routed right. When a query goes to the small model and the answer looks fine, we can’t be sure the premium reasoning model wouldn’t have been meaningfully better without running both, which defeats the point of routing in the first place.
Our plan is shadow routing: send a small slice of traffic, say 10%, to both models in parallel and compare. That tells us how often the small model’s answer is genuinely indistinguishable, how often routing down actually hurt, and whether the router’s confidence is calibrated to real quality. Over time, thumbs-up and thumbs-down feedback from users feeds the same loop and lets us tune the threshold to our own query distribution rather than a textbook default.
Enterprise AI Routing Solution Delivered by OrchestROUTER
A working intelligent-routing proof-of-concept that decides where every query goes and validates the core RouteLLM hypothesis on enterprise models.
- Intelligent routing across enterprise Qwen models: one learned router, one decision per query
- The right model for every query: simple requests handled by the small model, premium reasoning models reserved for the ones that need it
- A pretrained Matrix Factorization router: about 100MB, downloaded once, zero retraining
- Low routing overhead: roughly 70 to 130ms, about 1 to 3% of total latency, lost in the noise of model inference
- Full-stack build: a React frontend and FastAPI plus RouteLLM backend in one deployable system
OpenAI-compatible enterprise inference integration: both Qwen models served behind standard endpoints, secured with bearer-token auth and HTTPS
Reflections on Building an Intelligent AI Routing Platform
Building OrchestROUTER taught us more about routing as a discipline than about any one model, and a few lessons stand out as we close.
Pretrained routers transfer, and that’s the unlock. The single most useful finding is that a router trained on one model pair routes a completely different pair well. Routing isn’t a bespoke ML project per deployment; it’s something you can adopt off the shelf.
The hard part is evaluation, not routing. Making a routing decision is fast and cheap. Knowing whether it was the right one, without paying to run both models, is the real engineering problem, and it’s where shadow routing and user feedback earn their keep.
One threshold is a surprisingly powerful lever. Matching queries to models usually sounds like a roomful of trade-off discussions. With OrchestROUTER it’s a dial between 0 and 1 that anyone can turn, with predictable effects.
Starting binary kept us honest. Two models instead of a fleet meant we proved routing actually works before taking on the complexity of specialized models. Focus first, scale later.
References and Further Reading
Framework and research
- RouteLLM (lm-sys, built with Anyscale): the open-source LLM routing framework this work is built on. github.com/lm-sys/RouteLLM
- Ong, I. et al. (2024), “RouteLLM: Learning to Route LLMs with Preference Data,” arXiv:2406.18665. arxiv.org/abs/2406.18665
- RouteLLM: An Open-Source Framework for Cost-Effective LLM Routing, LMSYS blog. lmsys.org/blog/2024-07-01-routellm
• Pretrained routers and datasets, RouteLLM on Hugging Face. huggingface.co/routellm
Models and data
- LMSYS Chatbot Arena, the human preference data behind the pretrained routers (Chiang et al., 2024). huggingface.co/lmsys
- Qwen model family, Qwen2.5-32B-Instruct and Qwen3-4B-Instruct. huggingface.co/Qwen | qwenlm.github.io
OpenAI text-embedding-3-small, the query encoder used by the router. platform.openai.com/docs/guides/embeddings
Intelligent query routing is fast rapidly becoming core infrastructure for enterprise AI, AI cost optimization, and multi-model LLM deployments. And we’re continuing to build on what OrchestROUTER taught us. If you’re weighing how routing could fit your own stack, the team at Cloud2 Labs Innovation Hub would be glad to compare notes.
Built at Cloud2 Labs Innovation Hub. OrchestROUTER is a proof-of-concept. Routing behavior reflects our own testing on this two-model pair, and results will depend on your model mix and traffic.